Trong thế kỷ 21, chúng ta đang chứng kiến một cuộc cách mạng thầm lặng nhưng đầy mạnh mẽ tại giao điểm của khoa học máy tính và sinh học. Sự bùng nổ của dữ liệu sinh học, từ trình tự gen cá nhân đến cấu trúc phức tạp của protein, đã tạo ra một kỷ nguyên mới – kỷ nguyên mà các thuật toán không chỉ phân tích mà còn giải mã sự sống. Đây chính là lĩnh vực của Computational Biology và Genomic Data Science.
Computational Biology có thể hiểu là ngành khoa học ứng dụng các phương pháp tính toán để phân tích, mô hình hóa và diễn giải dữ liệu sinh học. Trong khi đó, Genomic Data Science là một nhánh chuyên sâu hơn, tập trung vào việc xử lý và khai thác dữ liệu hệ gen (genomic data) khổng lồ. Sự kết hợp này không chỉ là những nghiên cứu lý thuyết trong phòng thí nghiệm. Ngược lại, nó đang trở thành một công cụ thiết yếu, trực tiếp góp phần vào việc chẩn đoán, phòng ngừa và chữa trị những căn bệnh nan y, mở ra hy vọng mới cho hàng triệu người trên toàn cầu.

Bản chất của ngành: Phân tích dữ liệu khổng lồ bằng sức mạnh tính toán
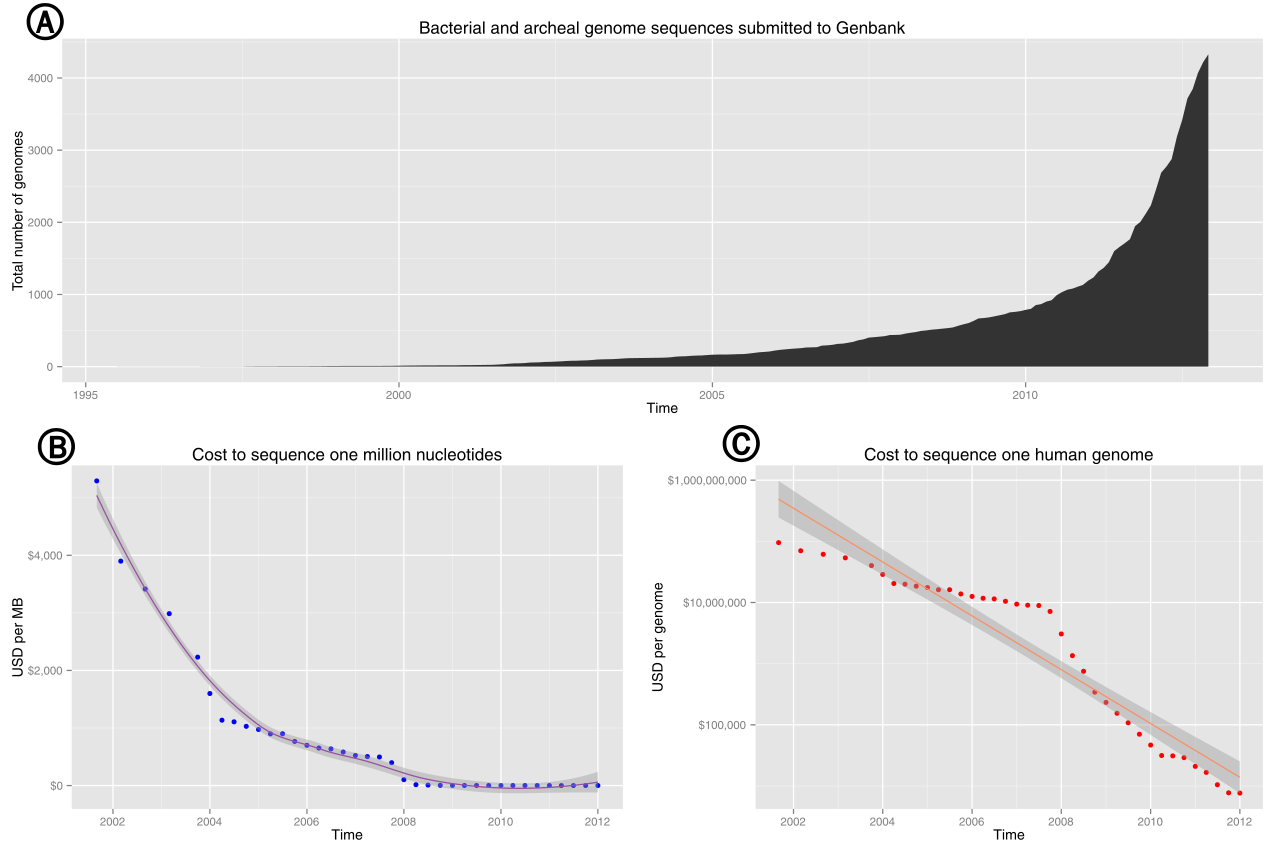
Thế giới sinh học ngày nay tràn ngập dữ liệu. Mỗi tế bào, mỗi gen, mỗi protein đều chứa đựng vô vàn thông tin. Tuy nhiên, việc “đọc hiểu” và trích xuất ý nghĩa từ hàng tỷ cặp cơ sở (base pairs) trong một hệ gen người hay hàng ngàn protein khác nhau đòi hỏi một sức mạnh tính toán vượt trội mà không một nhà khoa học nào có thể thực hiện thủ công. Đây là lúc Computational Biology và Genomic Data Science phát huy vai trò chủ chốt.
Từ dữ liệu thô đến tri thức: Các siêu máy tính và thuật toán tiên tiến đã trở thành “bộ não” không thể thiếu, xử lý và phân tích những tập dữ liệu khổng lồ này. Chúng không chỉ đơn thuần là sắp xếp thông tin, mà còn tìm kiếm các mẫu hình, mối liên hệ ẩn giấu và dự đoán các tương tác sinh học quan trọng. Quá trình này biến dữ liệu thô thành tri thức có giá trị, cung cấp cái nhìn sâu sắc về cơ chế bệnh tật, phát triển thuốc và cá thể hóa điều trị.
Sự dịch chuyển môi trường làm việc: Một trong những thay đổi đáng chú ý nhất của ngành Computational Biology là sự dịch chuyển môi trường làm việc. Ngành này không còn bó hẹp trong các phòng thí nghiệm truyền thống hay bệnh viện. Ngày nay, các chuyên gia Genomic Data Science đang được săn đón tại nhiều môi trường đa dạng và đổi mới:
- Sự tham gia của các “ông lớn” công nghệ: Với AlphaFold, DeepMind đã chứng minh sức mạnh của AI trong sinh học khi dự đoán chính xác cấu trúc protein 3D. Thành tựu này xóa bỏ rào cản thập kỷ, trực tiếp tăng tốc quy trình thiết kế thuốc và giải mã sự sống.
- Làm việc tại các Startup Biotech và Viện nghiên cứu AI toàn cầu: Làn sóng Startup Biotech và viện AI đang tập trung vào Computational Biology để phát triển y học tái tạo và liệu pháp gen. Đây là môi trường năng động cho các chuyên gia Genomic Data Science khai thác dữ liệu gen phục vụ y tế.
Những “Vũ khí” công nghệ cốt lõi trong ngành
Để giải mã sự sống, các nhà khoa học máy tính sinh học sử dụng một bộ công cụ và kỹ thuật tính toán tinh vi. Đây là những “vũ khí” giúp họ biến dữ liệu thô thành thông tin hữu ích.
Thuật toán sắp xếp chuỗi (Sequence Alignment)
Hãy tưởng tượng bạn có hai đoạn mã gen và bạn muốn biết chúng giống nhau hay khác nhau ở điểm nào. Đây chính là nhiệm vụ của thuật toán sắp xếp chuỗi.
-
Cách máy tính so sánh các đoạn mã di truyền: Các thuật toán này so sánh trình tự của DNA, RNA hoặc protein để xác định các vùng tương đồng, đột biến hoặc biến thể. Chúng tìm cách “khớp” các chuỗi sao cho số lượng khác biệt là nhỏ nhất, qua đó làm nổi bật các điểm chung và riêng biệt.
-
Ứng dụng trong việc truy vết nguồn gốc virus hoặc phát hiện gen gây ung thư:
-
Truy vết virus: Khi một loại virus mới xuất hiện, việc sắp xếp chuỗi gen của nó với các chủng đã biết giúp xác định nguồn gốc, tốc độ đột biến và tiềm năng lây lan, hỗ trợ phát triển vắc-xin và thuốc kháng virus.
-
Phát hiện gen gây ung thư: Bằng cách so sánh trình tự gen của tế bào ung thư với tế bào khỏe mạnh, các nhà khoa học có thể xác định các đột biến gen chịu trách nhiệm cho sự phát triển của khối u, từ đó đề xuất phác đồ điều trị nhắm mục tiêu.
-
Lập mô hình Protein 3D (3D Protein Modeling)
Protein là những “cỗ máy phân tử” thực hiện hầu hết các chức năng sinh học trong cơ thể. Chức năng của một protein phụ thuộc rất nhiều vào hình dạng 3D phức tạp của nó.
Tại sao hình dạng protein quyết định chức năng của nó? Giống như một chìa khóa chỉ có thể mở một loại ổ khóa nhất định, một protein chỉ có thể tương tác hiệu quả với các phân tử khác khi nó có hình dạng không gian chính xác. Sự thay đổi nhỏ trong cấu trúc 3D có thể làm mất chức năng hoặc gây ra bệnh tật.
Sử dụng Deep Learning để mô phỏng cách thuốc tương tác với protein trong cơ thể: Trước đây, việc xác định cấu trúc protein là một quá trình tốn kém và mất thời gian. Ngày nay, với sự tiến bộ của học sâu (Deep Learning) và các dự án như AlphaFold, chúng ta có thể dự đoán cấu trúc 3D của protein với độ chính xác cao. Điều này cực kỳ quan trọng trong việc thiết kế thuốc: các nhà khoa học có thể mô phỏng cách một loại thuốc tiềm năng sẽ “khớp” và tương tác với protein mục tiêu như thế nào, giúp tăng hiệu quả và giảm tác dụng phụ.
Thống kê sinh học nâng cao (Advanced Biostatistics)
Dữ liệu sinh học thường rất “nhiễu” và phức tạp. Để trích xuất thông tin đáng tin cậy, các kỹ thuật thống kê tinh vi là không thể thiếu.
-
Sử dụng xác suất thống kê để loại bỏ “nhiễu” trong dữ liệu sinh học: Dữ liệu từ các thí nghiệm sinh học có thể bị ảnh hưởng bởi nhiều yếu tố ngẫu nhiên. Thống kê sinh học giúp xác định liệu một kết quả có phải là thật sự ý nghĩa hay chỉ là sự trùng hợp ngẫu nhiên.
-
Dự đoán tỷ lệ thành công của các phương pháp điều trị mới: Trước khi một loại thuốc hoặc liệu pháp mới được đưa ra thị trường, nó phải trải qua các thử nghiệm lâm sàng nghiêm ngặt. Thống kê sinh học đóng vai trò trung tâm trong việc phân tích kết quả thử nghiệm, dự đoán tỷ lệ thành công, đánh giá rủi ro và xác định liều lượng tối ưu, đảm bảo an toàn và hiệu quả cho bệnh nhân.
Triển vọng 2026: Kỷ nguyên của Y học cá nhân hóa (Personalized Medicine)
Bước vào năm 2026, lĩnh vực Computational Biology và Genomic Data Science đang đứng trước ngưỡng cửa của một kỷ nguyên mới: Y học cá nhân hóa. Đây không còn là khái niệm viễn tưởng mà đang trở thành hiện thực, đặc biệt ở các quốc gia phát triển.
-
Xu hướng tại Mỹ và các nước phát triển: Hoa Kỳ đang dẫn đầu xu hướng này với những khoản đầu tư khổng lồ vào các dự án giải mã gen quy mô lớn. Mục tiêu là tạo ra các phác đồ điều trị riêng biệt cho từng cá nhân, dựa trên cấu trúc gen, môi trường sống và lối sống của họ. Thay vì áp dụng “một loại thuốc cho tất cả mọi người”, y học cá nhân hóa hứa hẹn đưa ra những giải pháp tối ưu nhất, nâng cao hiệu quả điều trị và giảm thiểu tác dụng phụ.
-
Tác động xã hội trực tiếp:
-
Điều trị ung thư: Genomic Data Science cho phép các bác sĩ phân tích gen của khối u để xác định các đột biến cụ thể. Từ đó, họ có thể lựa chọn loại thuốc nhắm mục tiêu (targeted therapy) hoặc liệu pháp miễn dịch phù hợp nhất, tăng cơ hội chữa khỏi và cải thiện chất lượng cuộc sống cho bệnh nhân ung thư.
-
Bệnh hiếm: Với hàng ngàn bệnh hiếm gặp, việc chẩn đoán thường rất khó khăn và mất nhiều năm. Bằng cách phân tích dữ liệu gen của bệnh nhân, Computational Biology có thể rút ngắn thời gian chẩn đoán từ hàng năm xuống chỉ còn vài ngày hoặc vài tuần, giúp bệnh nhân nhận được sự chăm sóc kịp thời.
-
Phòng ngừa bệnh: Dựa trên phân tích gen, chúng ta có thể dự đoán nguy cơ mắc một số bệnh di truyền hoặc bệnh mãn tính như tiểu đường, tim mạch, từ đó đưa ra các khuyến nghị về lối sống và phòng ngừa sớm.
-
-
Cơ hội cho dân Computer Science: Thay vì chỉ tối ưu hóa các thuật toán quảng cáo hay hệ thống thương mại điện tử, bạn có thể trực tiếp tham gia vào cuộc chiến chống lại bệnh tật, phát triển các công cụ giúp cứu sống con người và cải thiện sức khỏe cộng đồng.
Lộ trình trở thành một Genomic Data Scientist cho người mới
Nếu bạn đang cảm thấy hứng thú với lĩnh vực đầy tiềm năng này và muốn trở thành một Genomic Data Scientist, đây là một lộ trình gợi ý:
-
Kỹ năng lập trình: Python và R là hai ngôn ngữ lập trình trong Computational Biology. Python với các thư viện mạnh mẽ như Pandas, NumPy, Scikit-learn và TensorFlow/PyTorch (cho Deep Learning) là công cụ không thể thiếu. R thường được ưa chuộng hơn cho các phân tích thống kê chuyên sâu và trực quan hóa dữ liệu sinh học. Ngoài ra, khả năng làm việc với Linux/Bash để xử lý dữ liệu trên các máy chủ tính toán hiệu năng cao cũng rất quan trọng.
-
Kiến thức nền tảng:
-
Sinh học phân tử cơ bản: Hiểu biết về DNA, RNA, protein, gen, di truyền học và các quá trình sinh học cơ bản là nền tảng để bạn có thể hiểu được ý nghĩa của dữ liệu mình đang phân tích.
-
Xác suất thống kê: Đây là kiến thức cốt lõi để bạn có thể thiết kế các thử nghiệm, phân tích dữ liệu một cách khoa học, đưa ra kết luận đáng tin cậy và hiểu được ý nghĩa của các mô hình dự đoán.
-
-
Công cụ chuyên ngành:
-
Thư viện BioPython (cho Python) và Bioconductor (cho R): Đây là các thư viện được thiết kế đặc biệt để xử lý dữ liệu sinh học, bao gồm chuỗi DNA/protein, phân tích trình tự, v.v.
-
Các cơ sở dữ liệu sinh học: Làm quen với các cơ sở dữ liệu công khai lớn như NCBI (National Center for Biotechnology Information), Ensembl (genome database) để truy xuất dữ liệu gen, protein và các thông tin liên quan.
-
Công cụ phân tích dữ liệu gen: Hiểu biết về các phần mềm và thuật toán chuyên biệt cho phân tích GWAS (Genome-Wide Association Studies), RNA-seq, Variant Calling, v.v.
-
Kết luận
Computational Biology và Genomic Data Science không chỉ là một xu hướng khoa học nhất thời; chúng đang định hình lại tương lai của y học và sức khỏe toàn cầu. Từ việc giải mã bí ẩn của bệnh tật đến việc thiết kế các liệu pháp cá nhân hóa, sức mạnh của thuật toán và dữ liệu đang mở ra những chân trời mới mà trước đây chúng ta chỉ có thể mơ ước
Nếu bạn là người yêu thích giải quyết vấn đề bằng thuật toán, có niềm đam mê với khoa học và mong muốn đóng góp trực tiếp vào sức khỏe cộng đồng, thì đây chính là thời điểm vàng để dấn thân vào lĩnh vực đầy hứa hẹn này. Hãy bắt đầu hành trình của bạn ngay hôm nay để trở thành một phần của cuộc cách mạng y học thế hệ mới, nơi mà mỗi dòng mã bạn viết ra có thể mang ý nghĩa cứu sống một mạng người.
Liên hệ Study USA để được hỗ trợ chi tiết.